The Challenges of Securing Data Access in the Cloud, Part 4 (of 4)
Part 4 (of 4) - Sharing and Chaining Roles

In this series of posts, I have shared my view on why Identity and Data security in the cloud is so complicated, and why many organizations get it wrong. If you missed part 1, part 2, or part 3, I recommend you read those first.
In my last post, I began exploring how to achieve least privilege in an AWS cloud environment. We discovered that although intuitively this task does not appear to be too complex, in practice, this is easier said than done and that simple role-based access is not enough to achieve least privilege. I gave some basic example use-cases (e.g. application assuming a role with excessive privileges) to understand the challenges, explained some important tools like IAM Access Advisor, and shared their limitations.
Now, let’s step up the game a bit. Consider a totally uncommon situation (yeah, right) where two different services within an application, or even two completely different applications, assumed the same role. As before, this specific role has access permissions to Amazon ElastiCache, RDS, DynamoDB, and S3 services.

Another look at Access Advisor reveals a more complicated reality.

It appears that all the services defined within the role are actually being accessed. From here, check whether the applications actually require access to all of the resources in these specific service types and whether full access privileges make sense. Then, adjust the permissions as required. In this case, however, there is an additional issue that has to be addressed.
In this case, each application is using a different set of services. In fact, while App1 RDS and ElastiCache services, App2 uses ElastiCache, DynamoDB and S3. Therefore, to achieve least-privilege, the correct action would not be simple role rightsizing, but role splitting first, followed by appropriate rightsizing.

To correctly analyze the situation and find an appropriate mitigation, dig deep into the CloudTrail logs and the compute management infrastructure (e.g. ECS, EKS, native Kubernetes) to correlate access actions to specific services with the compute resource running the relevant applications (App1 and App2). This is clearly not a straight-forward task in terms of data collection or analytics.
A similar situation occurs fairly often with federated users (i.e. users defined on an external, trusted Identity Provider (IdP) system, such as Okta, G-suite, or Active Directory). When these users connect to AWS, they automatically assume a role based on the definitions of the IdP within the environment. More often than not, multiple users assume the same role.

Similar to the previous use case, to correctly analyze and resolve the situation, you will have to properly correlate CloudTrail and IdP logs. As before, this is a challenge both in terms of data collection and analytics.
If this was not complex enough for you, consider the following scenario (at Ermetic, we refer to this scenario as role chaining):
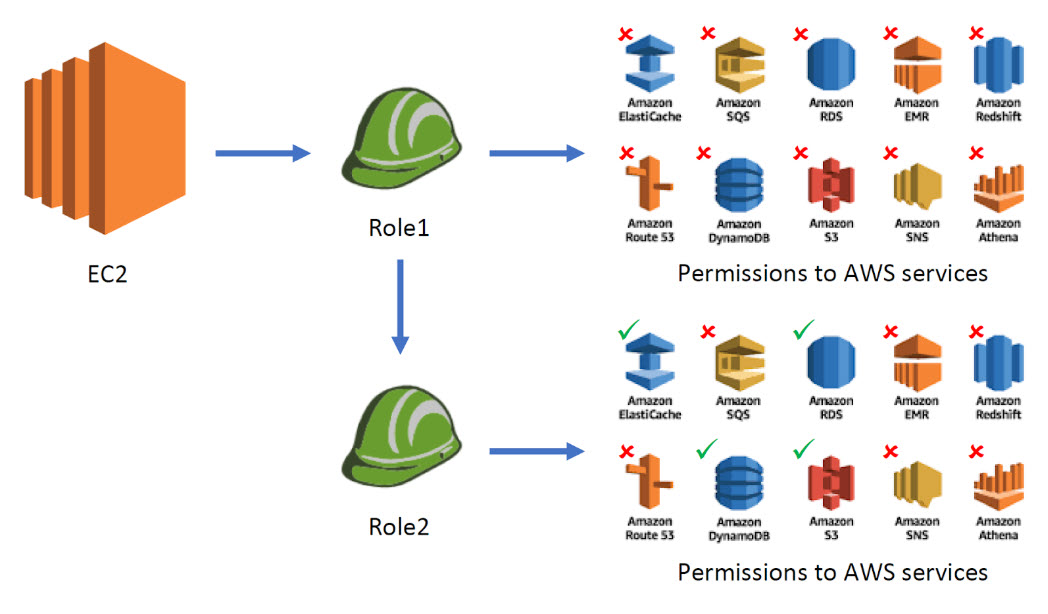
As you can see, the role (Role1) that our application is able to assume does not really have any dangerous permissions. However, Role1 has the permission to assume a different, more privileged role (Role2), which has permission to access a variety of services like Amazon ElastiCache, RDS, DynamoDB, and S3. If you examine the permissions attached to Role1, you can easily see the policy allows it to assume Role2:

This kind of role chain could consist of more than two roles. To really understand and rightsize access permissions, you must be able to map the role chains within and between accounts.
So far, we have touched only on native IAM access controls. However, there are several additional issues one should consider when mapping access permissions to resources, such as indirect access, or resource-level access controls.
We’ll dig into those another time...




